樓市降溫信號明確 二手房成交創五年新低,增城區領跌市場
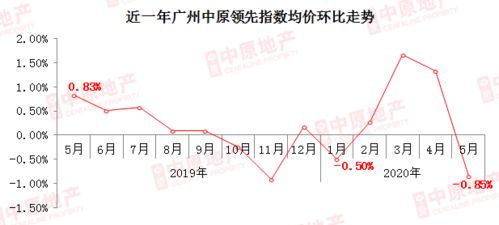
房地產市場的降溫趨勢愈發明顯。根據最新數據顯示,二手房成交量已降至五年來的最低點,其中增城區的跌幅尤為顯著,引發市場廣泛關注。這一現象背后,是多重因素交織作用的結果。
市場數據顯示,當前二手房交易量僅為47852宗,不僅較去年同期大幅下滑,更是創下了近五年來的新低。這一數據直觀反映出市場活躍度的下降,買賣雙方觀望情緒濃厚,交易節奏明顯放緩。
在整體市場低迷的背景下,增城區成為跌幅最為猛烈的區域。分析人士指出,增城區此前由于價格相對較低、供應量大,吸引了大量投資者和剛需購房者。但隨著市場調控政策的持續深化,以及部分區域配套發展不及預期,投資需求顯著退潮,導致該區域市場壓力尤為突出。價格回調幅度較大,進一步影響了購房者的入市信心。
易線通房產的分析認為,當前市場正處于深度調整期。一方面,持續的房地產調控政策旨在遏制投機炒作,促進市場長期健康發展,短期內對交易量產生了一定抑制。另一方面,宏觀經濟環境的變化、購房者對未來收入預期的謹慎態度,以及“買漲不買跌”的心理,共同導致了市場需求的收縮。
面對如此市場環境,買賣雙方均需調整心態。對于賣家而言,合理定價、正視市場現狀是關鍵;對于買家來說,這可能是一個仔細甄選、尋找價值洼地的時機。專家預計,在市場機制和政策引導的雙重作用下,二手房市場或將逐步尋求新的平衡點,但短期內復蘇動能可能依然有限。
二手房交易量創下五年新低,特別是增城區的深度調整,為整個房地產市場敲響了警鐘。這預示著行業正從高速增長階段轉向更加注重質量和穩定的新發展階段。未來市場的走向,將更加依賴于實體經濟的支撐、長期政策的引導以及居民實際居住需求的釋放。
最新產品

2020興義金秋購物節暨房地產展示交易會火熱招商中——易線通房產邀您共贏購房新機遇

神州通城西印象 優點、不足與周邊房產中介經紀人評價分析
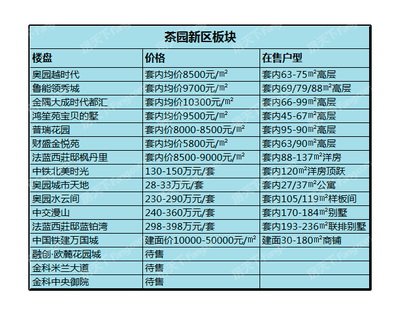
2017重慶買房攻略 南岸區區域解*

福州二手房市場回暖信號明顯 解析1月交易量創五年新高背后的深層含義
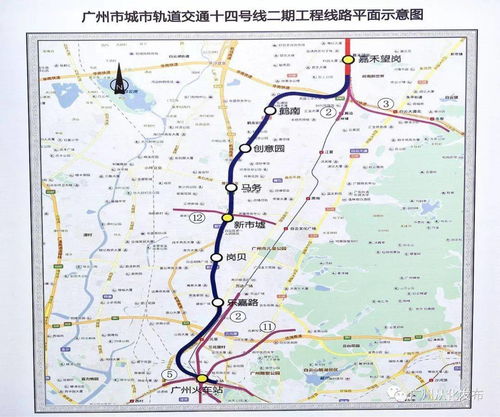
地鐵十四號線二期最新進展 預計2021年建成開通,沿線房產價值迎來新機遇
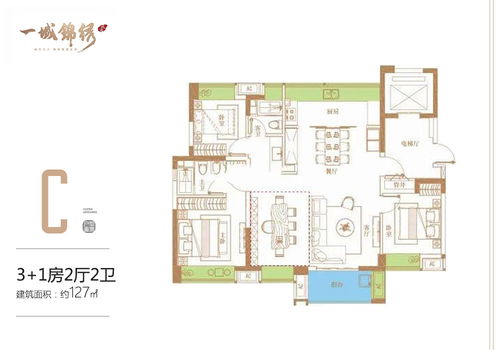
誠通·一城錦繡C戶型解析 127㎡三房兩廳兩衛,盡攬海南詩意棲居

上海浦東康橋湯巷馨村二期二手房解析 11號線秀沿路站旁的南北通透明居

四季花城電梯房黃金樓層三室兩衛,精裝拎包即住,首次出租

綠升牌橄欖酒榮獲生態原產地產品保護認證,易線通房產助力可持續發展

易高家居合肥下塘生產基地迎來首批8條德國豪邁生產線,智能化升級再提速